Google researchers developed a technique called Infini-attention, which allows LLMs to handle infinitely long text without increasing compute and memory requirements.
The Transformer architecture of an LLM is what allows it to give attention to all of the tokens in a prompt. The complex dot-product and matrix multiplications it performs are quadratic in complexity.
This means that doubling the tokens in your prompt results in a requirement of four times more memory and processing power. This is why it’s so challenging to make LLMs with large context windows without having memory and compute requirements skyrocket.
In a “standard” LLM, information at the beginning of the prompt content is lost once the prompt becomes larger than the context window. Google’s research paper explains how Infini-attention can retain data beyond the context window.
How does Infini-attention work?
Infini-attention combines compressive memory techniques with modified attention mechanisms so that relevant older information isn’t lost.
Once the input prompt grows beyond the context length of the model, the compressive memory stores information in a compressed format rather than discarding it.
This allows for older, less immediately relevant information to be stored without memory and compute requirements growing indefinitely as the input grows.
Instead of trying to retain all the older input information, Infini-attention’s compressive memory weighs and summarizes information that is deemed relevant and worth retaining.
Infini-attention then takes a “vanilla” attention mechanism but reuses the key value (KV) states from each subsequent segment in the model rather than discarding them.
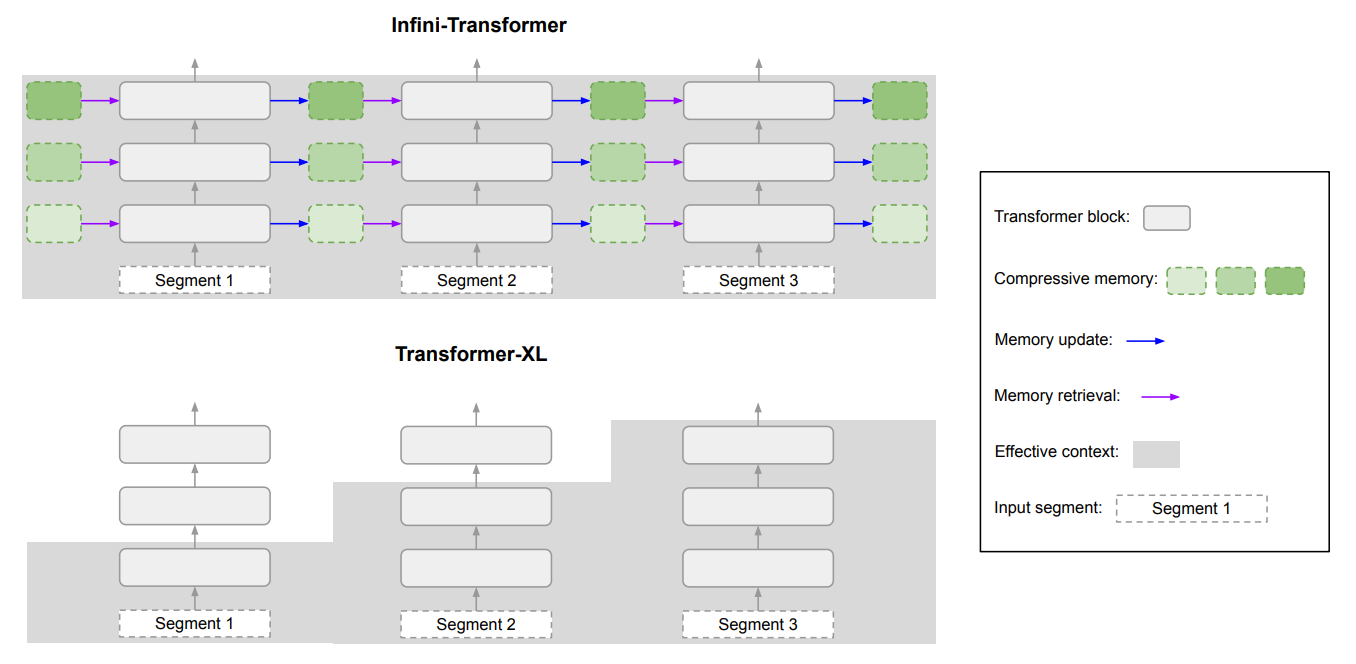
Here’s a diagram that shows the difference between Infini-attention and another extended context model Transformer XL.
Infini-Transformer (top) has an entire context history whereas Transformer-XL(bottom) discards old contexts since it caches the KV states for the last segment only. Source: arXiv
The result is an LLM that gives local attention to recent input data but also carries continuously distilled compressed historical data to which it can apply long-term attention.
The paper notes that “This subtle but critical modification to the attention layer enables LLMs to process infinitely long contexts with bounded memory and computation resources.“
How good is it?
Google ran benchmarking tests using smaller 1B and 8B parameter Infini-attention models. These were compared against other extended context models like Transformer-XL and Memorizing Transformers.
The Infini-Transformer achieved significantly lower perplexity scores than the other models when processing long-context content. A lower perplexity score means the model is more certain of its output predictions.
In the “passkey retrieval” tests the Infini-attention models consistently found the random number hidden in text of up to 1M tokens.
Other models often manage to retrieve the passkey towards the end of the input but struggle to find it in the middle or beginning of long content. Infini-attention had no trouble with this test.
The benchmarking tests are very technical but the short story is that Infini-attention outperformed the baseline models in summarizing and handling long sequences while maintaining context over extended periods.
Significantly, it retained this superior retention capability while requiring 114x less memory.
The benchmark results convince the researchers that Infini-attention could be scaled to handle extremely long input sequences keeping the memory and computational resources bounded.
The plug-and-play nature of Infini-attention means it could be used for continual pre-training and fine-tuning of existing Transformer models. This could effectively extend their context windows without requiring complete retraining of the model.
Context windows will keep growing, but this approach shows that an efficient memory could be a better solution than a large library.




