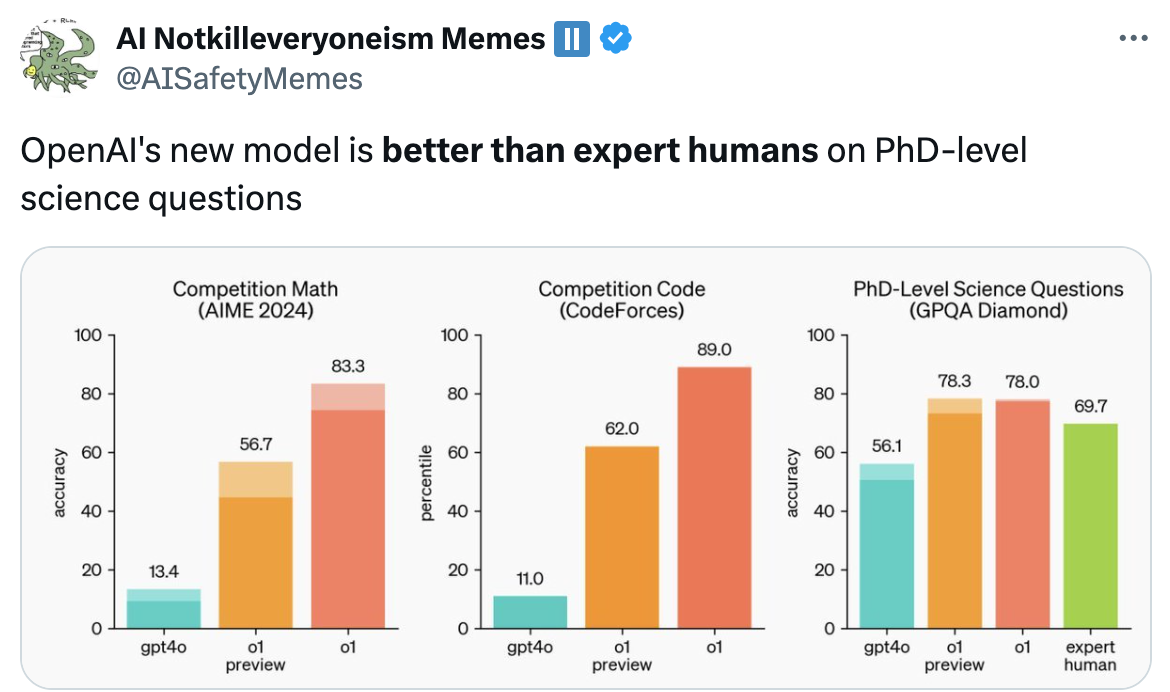
Dylan Hadfield-Menell presenting in MIT AI Ventures Class
John Werner
In last week’s class, we got a visit from MIT CSAIL Assistant Progressor Dylan Hadfield-Menell, who presented some really central questions about how we measure what AI does.
This really gets under the skin of what a lot of us have been pondering, about the more ambiguous characteristics of these technologies, specifically, using the example of computer vision and classification.
Starting out with the axiom that “data is the subjective property of the world,” Dylan moved directly into an explanation of how we have to think critically about AI.
“I want to know if a picture is a picture of a cat,” he said. “And so there is a real answer to that question. Right? I took a picture with my camera. There’s either a cat …that created the light that produced those pixels that are stored in my file, or there isn’t, right? That’s a real answer, correct objective, true or false?
Shot of a programmer working on a computer code at night
getty
Schrodinger’s cat, indeed!
Further, Dylan suggests, as we create new synthetic data, the question gets more complicated. He talked about applying the concept of “adversarial examples” which he defined as “this property of machine learning systems where you can add in a tiny imperceptible change, and reliably cause almost any machine learning classifier to misclassify the image.”
Dylan Hadfield-Menell
John Werner
In the above example, suppose you take a picture of an actual cat, and make slight (or more than slight) changes to it. (And, importantly, who decides what’s “slight” or not?)
Dylan posed the question: if the classifier decides it is a picture of a cat, (or it isn’t,) is the result “wrong”?
“The modified image is no longer something that was generated by a real cat,” he said. “It’s just a change to some digital pixels, right? So, in principle, who’s to say the machine is wrong and misclassifying that, and I’m right? … We know it’s still a picture of a cat. But I’m trying to push the boundaries of what these things mean. … when we program AI systems, we program them with data – we tell them, here’s what I want you to say, here’s an example of a good output. Here’s an example of a bad output. And the thing that I want to convince you (of) about AI systems, the thing I want you to take home from this, is that the data we use to program those systems is much more like a Python program, or a C program, where we write code inside of a computer and tell it what to do, than it is a reflection of the real world. People say ‘I want better data,’ or ‘I want more accurate data.’ And that’s not actually true. … is you want a better model.”
Now, thinking about this, we get these twists on determinism as we dig into AI systems, and we have to figure out where the limits really are. So I think Dylan’s example is fundamental to understanding the limits of classification.
Data selection choices, he pointed out, are programming choices. (That makes sense. Think about “programming choices of omission.” That’s potentially confusing, right?)
“When we are building AI systems, when we select data to train them on, the primary thing we are doing is specifying a subjective idea of what we want the system to do,” he explained.
He gave the example of ChatGPT, where suddenly, people were reacting to its outputs, suggesting that the model had become “lazy.”
“Can you actually tell me what it was what was actually wrong?” he asked, giving another example: a toaster. Essentially, he noted, we have pretty good definitions for what a toaster is supposed to do – how dark the bread gets, etc. But with ChatGPT, he suggested, it’s really not that simple, and there’s the potential for people to get confused about how the model is delivering, based on training.
“It’s not that it actually got worse,” he said, in terms of what he called the ChatGPT “hullabaloo” of months ago. “It’s just that they were evaluating it incorrectly… it’s complicated to tell the systems what you want them to do. In fact, we don’t usually know what we want systems to do. And system designers are tweaking a whole bunch of things, collecting a bunch of data as an opaque way of programming it to do what they want it to do. So what do we actually do? What’s kind of the pathway forward?”
Developers, he noted, will want to think about what it means for a model to “work,” and when it does or doesn’t “work,” based on some defined principles that can be, well, hard to define.
“(These types of determinations will be) one of the biggest areas of progress in taking AI systems from the lab, into a dependable building block that we integrate into our economy and our businesses,” he said. “If you’re thinking about areas where there’s the opportunity for large impact in the development of AI systems, I think it’s not necessarily about making it better, or more accurate at predicting, predicting supposedly ‘accurate’ data, supposedly ‘objective’ data. It’s about conveying: what was the goal of the subjective choices that the designers made?”
That ability to explain the targeting and nature of AI model work, he theorized, will be central to AI planning.
“(It’s) a central and key property that we need, if we are actually going to get the benefits from AI that we want to get,” he said.
I thought this was all great fodder for thought, for the students, who will be crafting elevator pitches, developing models, and generally trying to define AI in the next generation. Look for more here on all of our great guests and their insights!
Portrait of Dylan Hadfield-Menell
Katherine Taylor